“倾斜”对某些数据来说是自然的特征。
什么是数据倾斜
简单地说,数据倾斜就是分区的数据不均衡地分布。很多数据天然就是易“倾斜”的,比如国家的人口、互联网上网站的访问量等等。
Spark 中的 skew join
在 Spark 中,像 SortMergeJoin/ShuffleHashJoin 这样要求输入数据分区的,容易受数据倾斜的影响;像 BroadcastHashJoin 就比较不容易受数据倾斜的影响,因为它不要求输入数据分区,但它要求 join 的其中一方数据集要足够小。skew join 可以认为是混合使用这两类 join 的的策略。
skew join 是“缓解”了数据倾斜的影响,并不是彻底“解决”了数据倾斜的特征。目前 Spark 实现 skew join 的主要策略有:skew hint, runtime skew mitigation 及 customized AQE skew mitigation 1。
Skew hint
这是一种基于规则的策略。在 Spark SQL 中使用 hint 来描述倾斜的数据的信息:
SELECT /*+ SKEWED_ON(a.column=key1,...) */ *
FROM table_A a
JOIN table_B b
ON a.column = b.column
Spark 根据 hint 的信息,将参与 join 的数据集根据倾斜的 key 分为两部分,对无倾斜的部分使用 SortMergeJoin/ShuffleHashJoin ,对倾斜的部分作 BroadcastHashJoin ,再将两个部分的结果 union 起来。
这种策略减少了运行时的延迟时间,但是要求事先知道具体是哪些 key 有倾斜(这样才能在 hint 中明确列出这些 key),而且对数据集遍历了两遍。
Runtime skew mitigation
这是基于 Spark 2 adaptive 框架的策略。Spark 2 的 adaptive framework 使得执行计划可动态调整,调整的依据是中间结果的统计信息。
过去一个作业执行过程中,所有 reducer 的个数是一样的,都是 spark.sql.shuffle.partitions 。Spark 2 在开启 adaptive execution 后,会通过 ExchangeCoordinator 根据运行时中间阶段的统计信息计算出下一阶段合适的分区数。 只会合并小的分区,不会拆分大的分区。这样一个 reducer 可能需要读取多个分区,Spark 新增接口,一次 shuffle read 可以读多个分区的数据。
通过收集 join input stage 的 MapOutputStatistics 信息,将一个分区的大小与下面的参数相比较:
min_threshold_config_vale: 如分区大小大于该值。median_ratio * median_size(shuffle): 如分区大小 N 倍于中位数大小。pct_99_ratio * pct99_size(shuffle): 如分区大小 N 倍于99百分位数大小。
来探测是否发生了数据倾斜。
自动拆分发生了数据倾斜的分区为几个更小的分区,另一方数据集对应的分区复制为相同数量的分区,参考Skewed Join Optimization Design Doc再 join 。
这种策略减少了运行时的延迟时间,不要求事先知道具体是哪些 key 上有数据倾斜,也不需要多次遍历数据集。但是会有额外的 shuffle 在 join 之间或者 join 与聚合操作之间,即使没有数据倾斜现象时也如此。
相关的参数有:
- spark.sql.adaptive.enabled
- spark.sql.adaptive.skewedJoin.enabled : 自动处理数据倾斜
- spark.sql.adaptive.skewedPartitionMaxSplits : 处理一个倾斜分区的 task 个数上限,默认 5 。
- spark.sql.adaptive.skewedPartitionRowCountThreshold : 行数低于该值的分区不会当作倾斜,默认值是1千万。
- spark.sql.adaptive.skewedPartitionSizeThreshold : 大小小于该值的分区不会当作倾斜,默认值是 64MB 。
- spark.sql.adaptive.skewedPartitionFactor : 倾斜因子,用来与各分区大小或行数的中位数相乘,默认是 10 。
Customized AQE skew mitigation
这是基于 Spark 3 AQE 框架的策略。Spark 3 的 Adaptive Query Execution 能在运行时调整 DAG ,主要是动态合并 shuffle 分区,动态调整 join 策略,动态优化数据倾斜的 join 2。
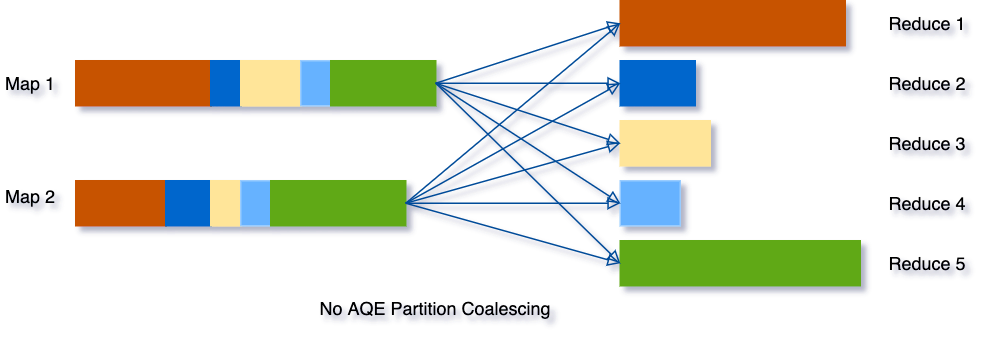
Spark AQE 动态合并 shuffle 分区:

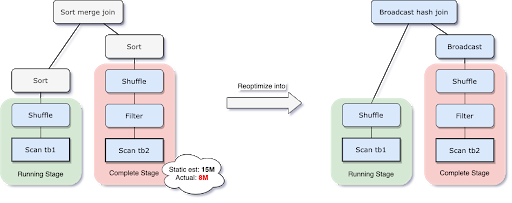
Spark AQE 动态调整 join 策略:
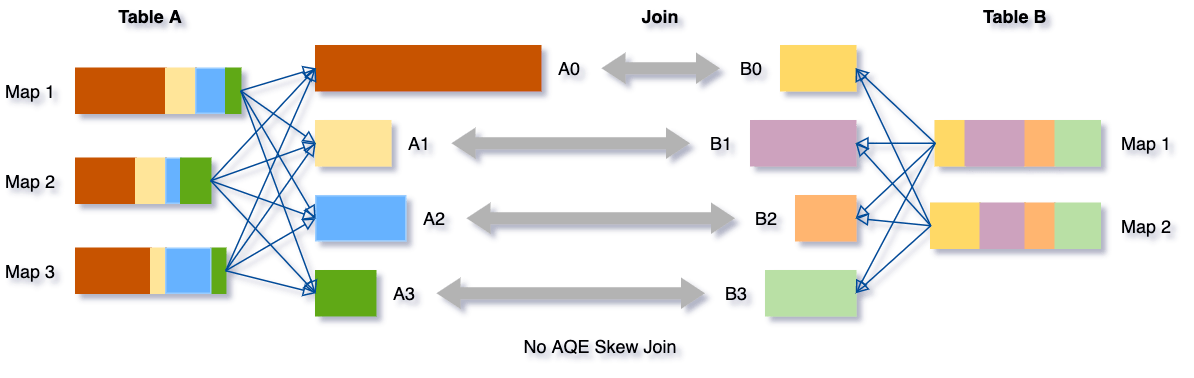
Spark AQE 动态优化数据倾斜:
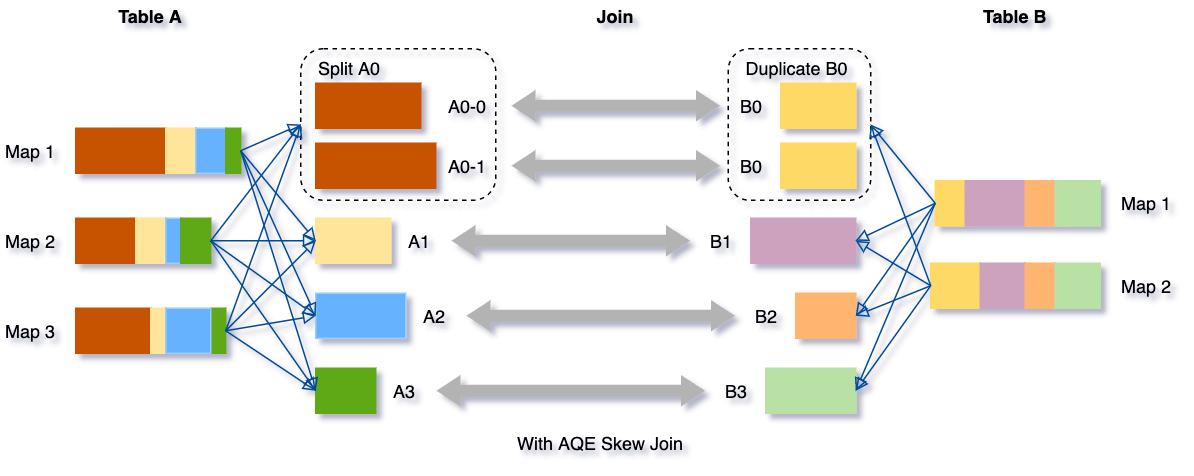
这种策略减少了运行时的延迟时间,不要求事先知道具体是哪些 key 上有数据倾斜,也不需要多次遍历数据集。没有数据倾斜时不会有额外的 shuffle 。
相关的参数有:
- spark.sql.adaptive.enabled
- spark.sql.adaptive.skewedJoin.enabled : 自动处理数据倾斜
- spark.sql.adaptive.skewedPartitionThresholdInBytes : 默认 256MB 。
- spark.sql.adaptive.skewedPartitionFactor : 默认为 5 。
当一个分区的大小同时满足大于 skewedPartitionThresholdInBytes 及 skewedPartitionFactor * 所有分区大小中位数 时,就被认为是“倾斜”的。
- spark.sql.adaptive.coalescePartitions.enabled : 默认 true ,动态合并 shuffle 分区。发生在 Shuffle Read 阶段,reduce side task 将数据分片全部拉回,AQE按照分区编号的顺序,依次把小于目标尺寸的分区合并到一起。
- spark.sql.adaptive.advisoryPartitionSizeInBytes : 默认 64MB 。
-
spark.sql.adaptive.coalescePartitions.minPartitionNum : 最小分区数,默认为集群的默认并行度。最终的targetSize为:首先计算出总的 shuffle 的数据大小 totalPostShuffleInputSize ; maxTargetSize 为 max(totalPostShuffleInputSize / minPartitionNum, 16); targetSize = min(maxTargetSize, advisoryPartitionSizeInBytes)。
-
spark.sql.adaptive.localShuffleReader.enabled : 默认 true ,动态调整 join 策略。
- spark.sql.autoBroadcastJoinThreshold : 广播阈值,默认 10MB 。
- spark.sql.adaptive.nonEmptyPartitionRatioForBroadcastJoin : 默认 0.2 。
当两张表完成 Shuffle Write 阶段后,AQE 会继续判断某一张表是否满足一下两个条件: 中间文件尺寸总和小于广播阈值 ;空文件占比小于配置项 nonEmptyPartitionRatioForBroadcastJoin 。只要有一个表满足就会把 Shuffle Joins 降级为 Broadcast Join(仅适用于 Shuffle Sort Merge Join)。两张大表 join,超过了广播阈值的话 Spark SQL 最初会选择 SortMerge Join ,AQE 只有结合两个表 join 中的 Exchange 才能进行降级判断,所以两张表必须都完成 map side task 且中间文件落盘。AQE 才会决定是否降级以及用哪张表做广播变量。
参考
- Suganthi Dewakar & Guanzhou(Tony)Xu. Skew Mitigation For Facebook's Patabyte-Scale Joins. DATA+AI SUMMIT EUROPE,2020. ↩
- Adaptive Query Execution: Speeding Up Spark SQL at Runtime ↩

Comments