Apache Spark 的 shuffle 描述的是数据从 map side task 输出到 reduce side task 输入的这段过程。
在 RDD 的依赖关系中,如果一个父 RDD 中的分区被不只一个子 RDD 中的分区所依赖,则称父子 RDD 之间存在宽依赖。只要有宽依赖的存在,则必定会有 shuffle 过程。通常,重分区的操作(repartition、coalesce)、各种 ByKey 算子、Join相关操作(cogroup、join 等)都会触发 shuffle 过程。
一次 shuffle ,map side 有和 RDD 的分区数相同数量的 task 执行;reduce side 默认取参数 spark.default.parallelism 或 spark.sql.shuffle.partitions 的值作为分区数(若该参数未配置,则取 map side 的最后一个 RDD 的分区数),分区数决定 reduce side 的 task 的数量。
参数 spark.default.parallelism 只有在处理 RDD 时才起作用;参数 spark.sql.shuffle.partitions 是对 DataFrame 起作用。
Spark 中每个 Stage 的每个 map/reduce side task 都会有唯一标识:mapId 和 reduceId 。每个 shuffle 过程也有唯一标识:shuffleId 。
基本过程
Spark 中负责 shuffle 过程的组件主要是 ShuffleManager ,默认的 ShuffleManager 是 SortShuffleManager 。
通常 shuffle 分为两个部分,在 map side task 阶段的数据准备阶段,称之为 Shuffle Write ;在 reduce side task 阶段的数据拉取/拷贝处理,称之为 Shuffle Read 。
前一个 Stage 的 ShuffleMapTask 进行 Shuffle Write ,把数据存储在 BlockManager 上并上报数据位置等元数据到 Driver 端的 MapOutputTrackerMaster ,下一个 Stage 根据这些信息进行 Shuffle Read ,拉取(本地读取/远程读取)上个 Stage 的输出数据(当前一个 Stage 的所有 ShuffleMapTask 都结束后再 fetch )存放到缓冲区,经过处理后的数据放在内存+磁盘上。
Spark 不要求 shuffle 后的数据全局有序,Shuffle Read 的时候是一边拉取数据,一边进行处理。
普通运行机制
在普通运行机制下,每个 map side task 数据先写入一个内存数据结构中。这个数据结构根据不同 shuffle 算子而不同。如果是聚合算子,则用 Map 数据结构,边聚合边写入内存;如果是连接算子,则用数组数据结构,直接写入内存。待内存容量到了临界值则溢写到磁盘。写到磁盘前先根据 key 排序,分批次(参数 spark.shuffle.spill.batchSize ,默认1万条)写入到磁盘的临时文件,最后合并这些临时文件为一个大文件。最后只剩下一个数据文件和对应的索引文件。
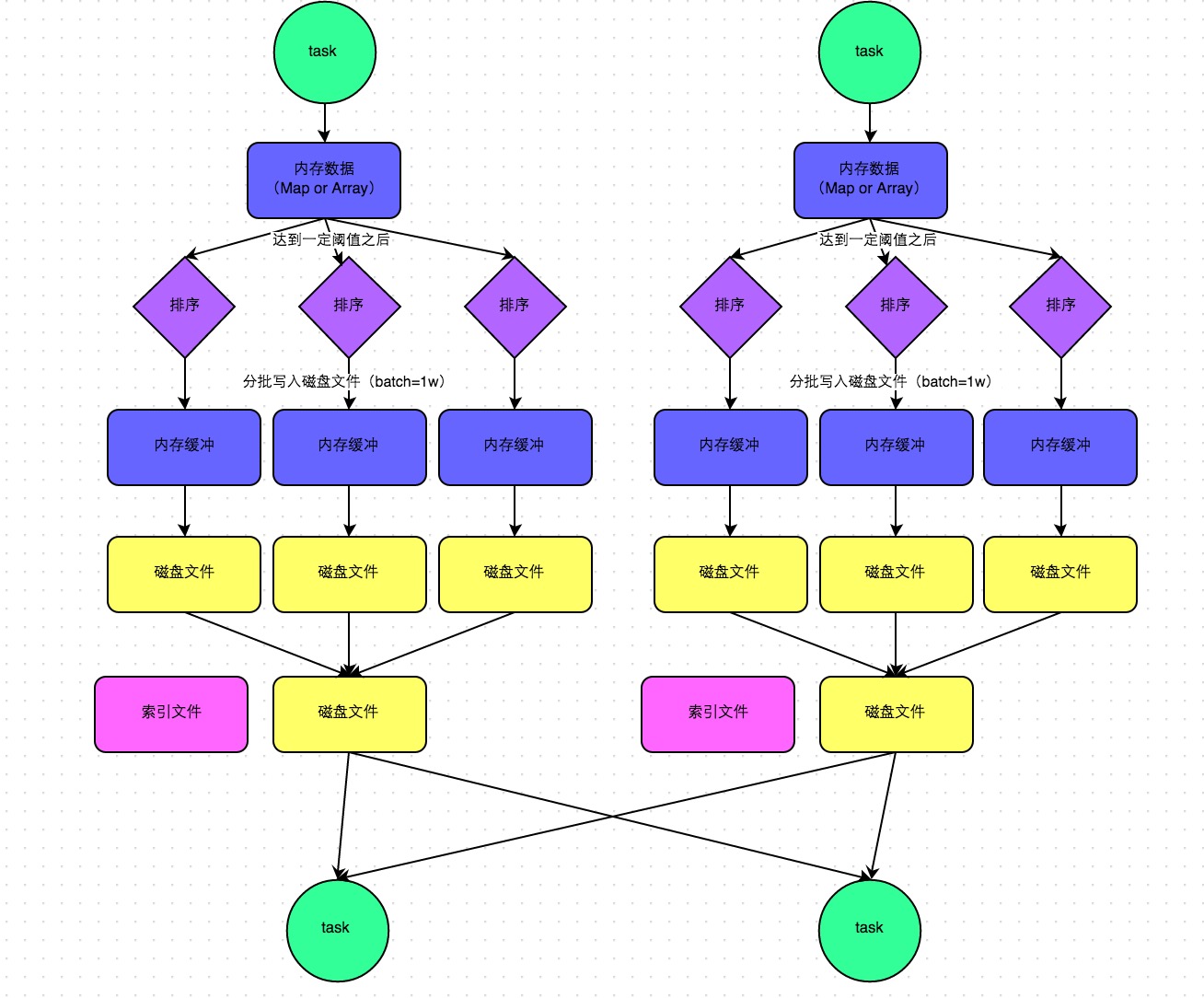
bypass 运行机制
当 map side task 的数量小于等于参数 spark.shuffle.sort.bypassMergeThreshold 的值(默认是200),且不是聚合类的算子时,就会启用 bypass 机制。
每个 map side task 会为每个下游 task 都创建一个临时磁盘文件,并对数据按 key 进行 hash 的值写入到对应的磁盘文件中。和普通机制类似,数据也是先写入内存的缓冲里,容量达到临界值再溢写到磁盘文件,最后也会将所有临时文件合并为一个大文件,创建一个对应的索引文件。
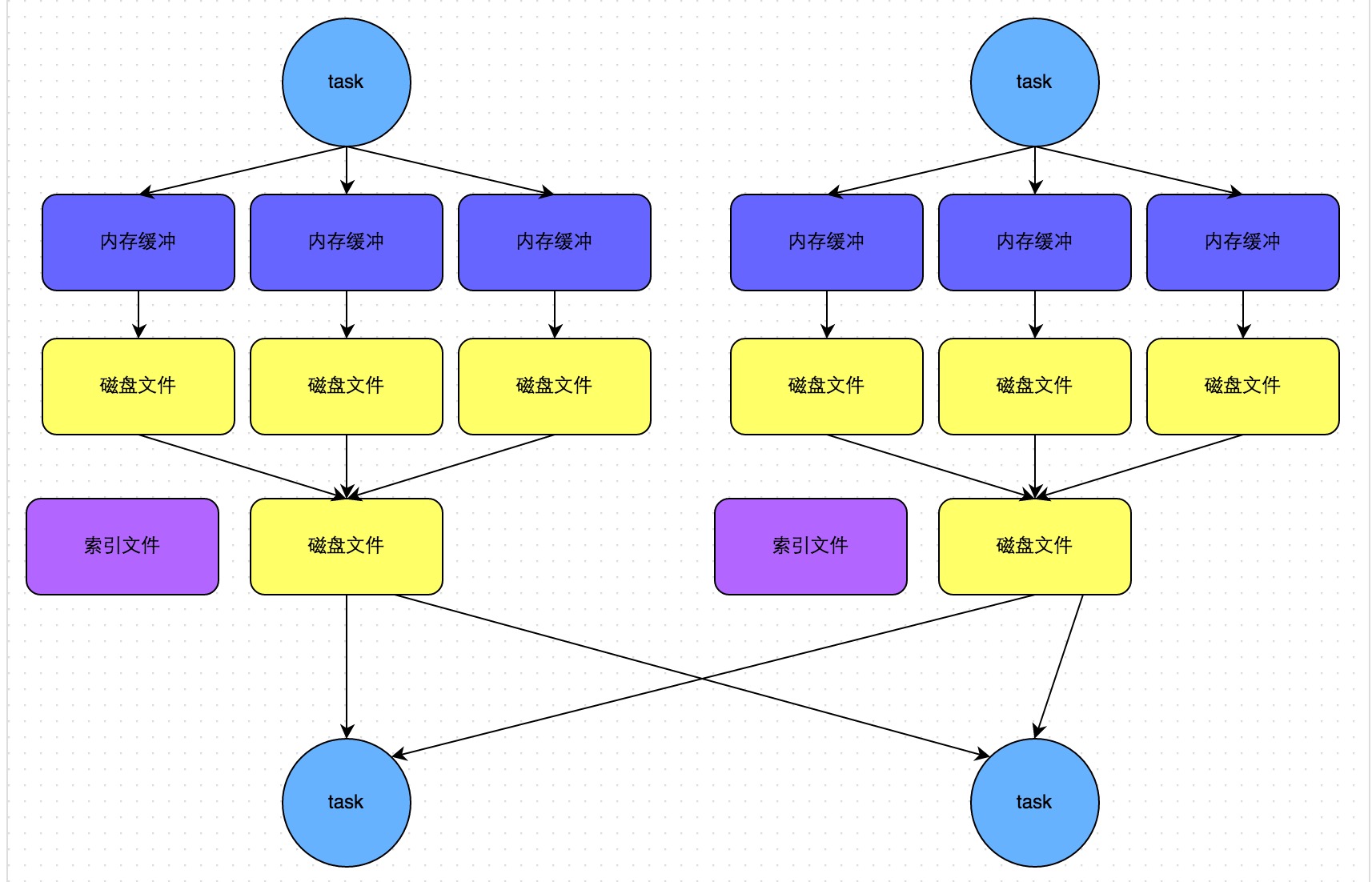
所以 bypass 机制其实就是用 hash 替代了普通机制里的排序,去掉了排序的开销。
历史演进
Spark 最初是基于 Hash 的 shuffle ,Shuffle Write 过程中产生大量文件(每个 map side task 产生数量与 reduce side task 数量相同的文件),Shuffle Read 过程中,对拉取到的数据不进行排序,用一个 HashMap 来合并数据,容易 OOM 。这个时期默认的 ShuffleManager 是 HashShuffleManager 。
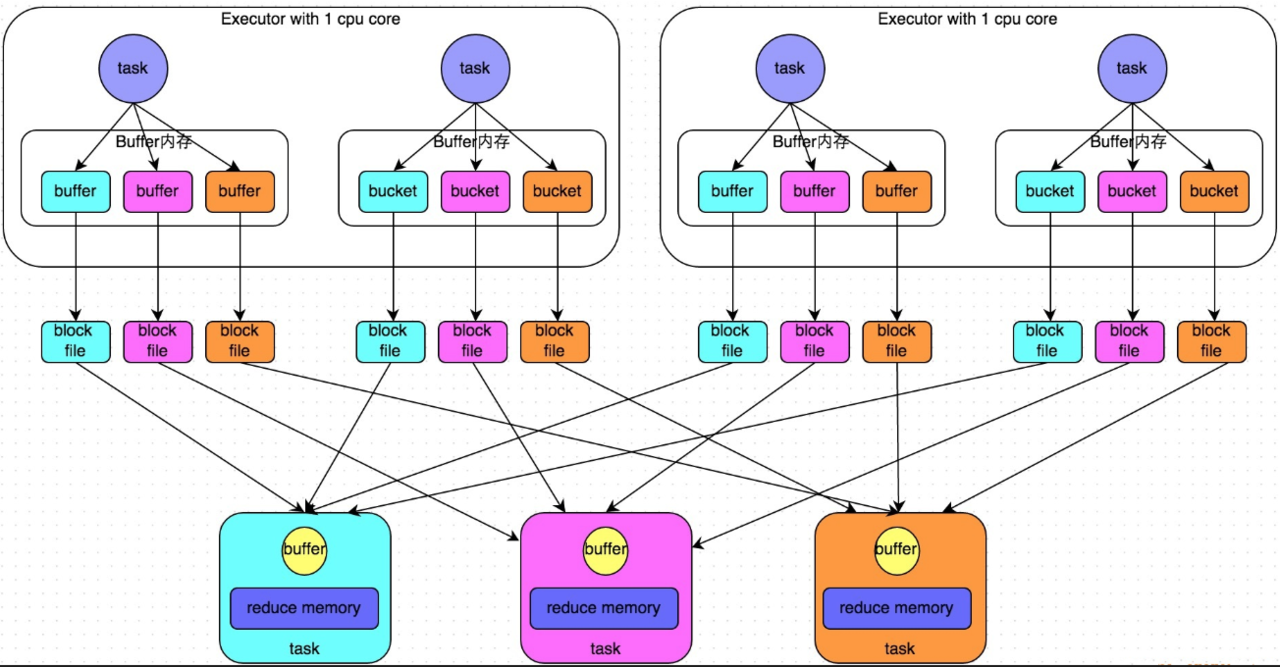
为了解决基于 Hash 的 shuffle 带来的问题,Spark 引入了类似 MapReduce shuffle 的基于排序的 shuffle 机制。Shuffle Write 过程中,map side task 将所有结果写入同一个文件 数据文件中的记录按分区id排序,分区内部再按照 key 排序。索引文件记录每个分区的大小和偏移量。,同时生成一个索引文件(减轻文件系统管理众多文件的压力,也更少占用内存中缓存。)。Shuffle Read 过程中,reduce side task 作合并用的是 ExternalAppendOnlyMap ,在内存不足时刷到磁盘,不容易 OOM 。
Spark 1.5.0 曾有过 Tungsten-Sort Based Shuffle (钨丝计划) 机制。它直接在序列化的二进制数据上排序,而不是 Java 对象上。但它对要求 shuffle 阶段不能有聚合操作,分区数也有限制。
从 Spark 1.6.0 开始,Spark 将上述的基于排序的 shuffle 机制与钨丝计划统一。在 Spark 2.0.0 后,去除了基于 Hash 的 shuffle 机制。所以目前 Spark 2 里只有一种 shuffle ,基于排序的 shuffle 。
- Spark 0.8及以前 Hash Based Shuffle
- Spark 0.8.1 为Hash Based Shuffle引入File Consolidation机制
- Spark 0.9 引入ExternalAppendOnlyMap
- Spark 1.1 引入Sort Based Shuffle,但默认仍为Hash Based Shuffle
- Spark 1.2 默认的Shuffle方式改为Sort Based Shuffle
- Spark 1.4 引入Tungsten-Sort Based Shuffle
- Spark 1.6 Tungsten-sort并入Sort Based Shuffle
- Spark 2.0 Hash Based Shuffle退出历史舞台
一些优化的点
shuffle 过程将会产生对内存、磁盘及网络资源的大量消耗,是较为“昂贵”的过程,应尽量减少 shuffle 的次数。必要时主动 shuffle ,比如重分区改变分区数/并行度,提高后续分布式运行速度。注意多个同时运行的 task 共享 Executor 的内存,这使得单个 task 可用内存减少。
参数 spark.shuffle.file.buffer (默认32KB) 设置 Shuffle Write 时溢写到磁盘前的缓存大小。如果作业可用内存资源较为充足,可以适当增加它的大小,减少溢写到磁盘的次数。
参数 spark.reducer.maxSizeInFlight (默认48MB) 设置 Shuffle Read 时缓存的大小。如果作业可用内存资源较为充足,可以适当增加它的大小,减少拉取数据次数,即减少网络传输的次数。
参数 spark.shuffle.io.maxReties 设置 Shuffle Read 拉取数据失败时的最大重试次数。参数 spark.shuffle.io.retryWait 设置 Shuffle Read 每次重试拉取数据时的等待间隔。一般的调优都是将提高重试次数,不调整重试等待间隔。
参数 spark.maxRemoteBlockSizeFetchToMem 设置从 Shuffle Read 溢写到磁盘的缓存阈值。合理设置它可以减少 OOM 的情况。

Comments