这里指的是 Hadoop 里的 MapReduce 。
MapReduce 简介
Hadoop 中的 MapReduce 是一个分布式的并行计算平台,主要进行离线批处理。MapReduce 这个名称借鉴的是函数式编程里的 map 和 reduce 。它刚开始出现的时候,就是为了与 MPI(Message Passing Interface) 竞争。MPI 编写复杂,容错能力差。MapReduce 编写再繁琐,也比 MPI 容易得多,降低了分布式编程的门槛;再加上与分布式文件系统 HDFS 的集成(意味着良好的扩展性和廉价),在工业界大数据处理领域战胜了 MPI 。
MapReduce 本身是一种编程模型 Hadoop 中的实现也叫 MapReduce 。,主要思想是利用 Map(映射) 和 Reduce(归约) 来对大规模数据集分而治之,进行并行计算。Hadoop 的 MapReduce 推崇“移动计算,而不是移动数据”,分配计算任务到离它所需数据“最近”的集群节点上,计算跟着数据走。
MapReduce 的多个任务之间存在依赖关系,前一个任务的输出是后一个任务的输入,构成了一个有向无环图 DAG 。每个 MapReduce 作业的输出结果都会落地到磁盘上,这造成了大量的磁盘 IO ,但也带来了高容错。
早期的 MapReduce 既要管理自己任务的调度,还要管理 Hadoop 集群资源的分配。MapReduce 2 专注于做一个计算框架,资源的管理由 YARN 或其他资源管理框架进行。MapReduce 是 Hadoop 的核心组件之一 Hadoop 核心三驾马车:Yarn、HDFS、MapReduce 。,Apache Hive 的默认执行引擎就是 MapReduce 。
MapReduce 作业运行过程
MapReduce v1 里的 JobTracker 和 TaskTracker 在 v2 中已经不存在了。MapReduce v2 运行在 YARN 上,JobTracker 被 ResourceManager/ApplicationMaster 替代。TaskTracker 被 NodeManager 替代。所以,一个 MapReduce 的作业涉及的角色一般有:
- Client ,客户端提交作业。
- YARN ResourceManager ,负责集群资源协调。
- YARN NodeManager ,负责分配和监控 Container 。
- ApplicationMaster ,负责协调 MapReduce 的作业。
- HFDS ,负责与其他实体共享作业涉及的文件。
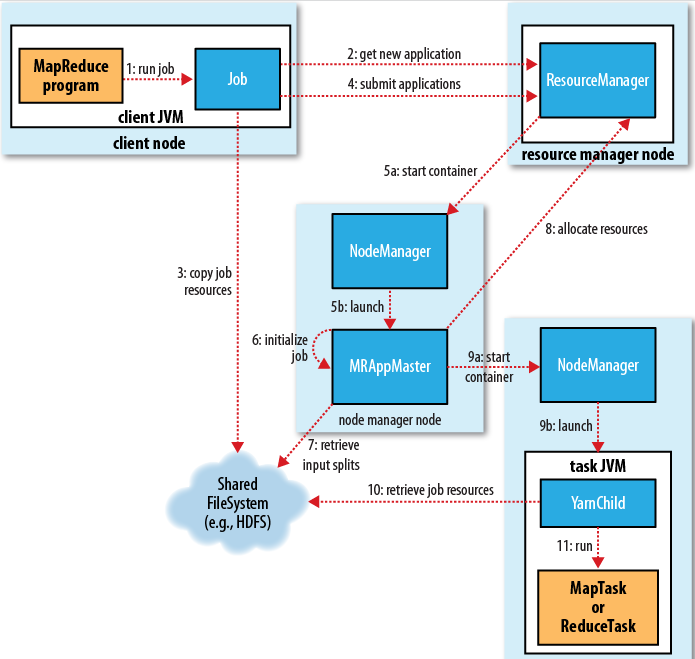
客户端向 ResourceManager 提交申请。ResourceManager 检查作业的输出配置、判断目录是否已经存在、权限等信息,如果接受申请,则返回一个 MapReduce 作业ID,以及该作业可用的 HDFS 上的路径。客户端计算作业的输入分片的大小,上传作业所需的 jar 包、配置文件等到 HDFS 上得到的路径默认会有10个副本,通过参数 mapreduce.client.submit.file.replication 控制,增加该值可以提高任务下载这些东西到本地时的效率。下。提交作业。
ResourceManager 先在一个 NodeManager 上分配第一个容器,用来启动 ApplicationMaster 进程。ApplicationMaster 启动后向 ResourceManager 注册并报告自己的信息,之后都由它来监控 Map 和 Reduce 任务的运行状态。
每个作业和作业里每个任务都有状态(pending,running,success,failure),作业运行时,客户端可与 ApplicationMaster 直接通信轮询作业的执行状态、进度等信息。
Map 阶段任务的工作机制简述: 输入文件被切割为多个输入分片再通过 RecordReader 按行读取内容给 Map 方法由用户自定义处理逻辑处理;处理完后由 OutputCollect收集器对结果按 key 分区(默认用 HashPartitioner)写入环形缓冲区,缓冲区达到一定阈值,按 key 排序溢写到磁盘上的临时文件;整个 Map 任务结束后合并所有溢写产生的临时文件,得到一个合并后的数据文件及相应的索引文件,等待 Reduce 任务拉取。
Reduce 阶段任务的工作机制简述: eventFetcher 获取已完成的 map 列表,由一些数据拷贝线程通过 HTTP 方式拉取属于自己的数据到内存缓冲区中,达到一定的阈值溢写到磁盘上的临时文件;拉取 map 端数据完成后,将众多溢写临时文件合并为一个大文件并排序;对排序后的键值对调用 Reduce 方法,最后写入结果到 HDFS 文件中。
Shuffle 阶段任务的工作机制简述: 一般把从 Mapper 产生输出开始到 Reducer 取得数据作为输入前的过程称作 Shuffle 。
Input 阶段
InputFormat 类 HDFS 上的文件基本是用的 FileInputFormat的子类: TextInputFormat 处理普通文本文件、SequenceFileInputFormat 处理 Sequence 文件。负责将输入数据划分为“输入分片”—— input split 。RecordReader 用于将 input split 的内容转换为KV键值对作为 Map 任务的输入。
输入分片,是逻辑分片,不会真正切割源文件;是根据分片的大小,逻辑上对源文件按字节进行划分。所以 input split 存储的并非数据本身,而是一个分片长度和一个记录数据位置的数组。1一个 Map 任务处理一个 input split ,因此 Map 任务的数量与 input split 的数量相同。
每个输入分片的大小是固定的,如果是读取 HDFS 的文件,则默认与 Block 的大小相同。 输入分片的大小并不是要接近 Block 大小才高效,这也要看集群的配置。
分片计算公式:
1 2 3 4 5 6 7 8 9 | |
如果输入数据是很多小文件,就有可能会产生很多分片,也就会产生大量的 Map 任务,导致低处理效率。一般都会先将小文件合并为大文件再上传到 HDFS 。或者使用 CombindFileInputFormat ,它将多个小文件从逻辑上划到一个 input split 中。
如果输入数据是很大的文件,则可以将 mapreduce.input.fileinputformat.split.minsize 从默认的 128MB 改为 256MB ,将 mapreduce.input.fileinputformat.split.maxsize 从默认的 128MB 改为 512MB 。
Map 阶段
ApplicationMaster 为 Map 任务发出资源申请请求。Map 任务执行的时候需要考虑到数据本地化的机制。
相关参数:
1 2 3 | |
每个 Map 任务是一个 Java 进程,它读取自己对应的输入分片,按用户实现的逻辑对各每个键值对作计算,计算完毕后,写入0个或多个键值对到本地磁盘。
Map 任务的个数一般是由输入分片决定的。在 Hive on MR 里,map 的个数还要看 Hive 是否启用了压缩且压缩算法是否支持文件切分,以及 hive.input.format 是什么实现类。2当 Hive 需要处理的文件是压缩且压缩算法不支持文件切分时,每个 map 处理的大小其实是文件的大小,这时只能通过调整 split.size 来减少(无法增加) map 个数。 Hive 默认在 map 前进行小文件合并。 当 Hive 处理的文件是不压缩的或者压缩算法支持文件切分,且 hive.input.foramt 为 HiveInputFormat 时,split.size 才可决定 map 个数。当 Hive 处理的文件是不压缩的或者压缩算法支持文件切分,但 hive.input.foramt 为 CombineHiveInputFormat 时,则控制 map 个数由以下四个参数起作用:
- mapred.min.split.size 或者 mapreduce.input.fileinputformat.split.minsize。
- mapred.max.split.size 或者 mapreduce.input.fileinputformat.split.maxsize。
- mapred.min.split.size.per.rack 或者 mapreduce.input.fileinputformat.split.minsize.per.rack。
- mapred.min.split.size.per.node 或者 mapreduce.input.fileinputformat.split.minsize.per.node。
set hive.input.format = org.apache.hadoop.hive.ql.io.CombineHiveInputFormat; --hive0.5开始就是默认执行map前进行小文件合并
set mapred.max.split.size = 256000000 --公司集群默认值
set mapred.min.split.size = 10000000 --公司集群默认值
set mapred.min.split.size.per.node = 8000000 --每个节点处理的最小split
set mapred.min.split.size.per.rack = 8000000 --每个机架处理的最小slit.
1.一般来说这四个参数的配置结果大小要满足如下关系: max.split.size >= min.split.size >= min.size.per.node >= min.size.per.rack 。
2.这四个参数的作用优先级: max.split.size <= min.split.size <= min.size.per.node <= min.size.per.rack 。当四个参数设置矛盾时,Hive 会以优先级最高的参数为准进行计算。
3.注意这四个参数可以选择性设置,可以选择性设置大小或者使用默认值,但仍遵循前两条规则。
Shuffle 阶段
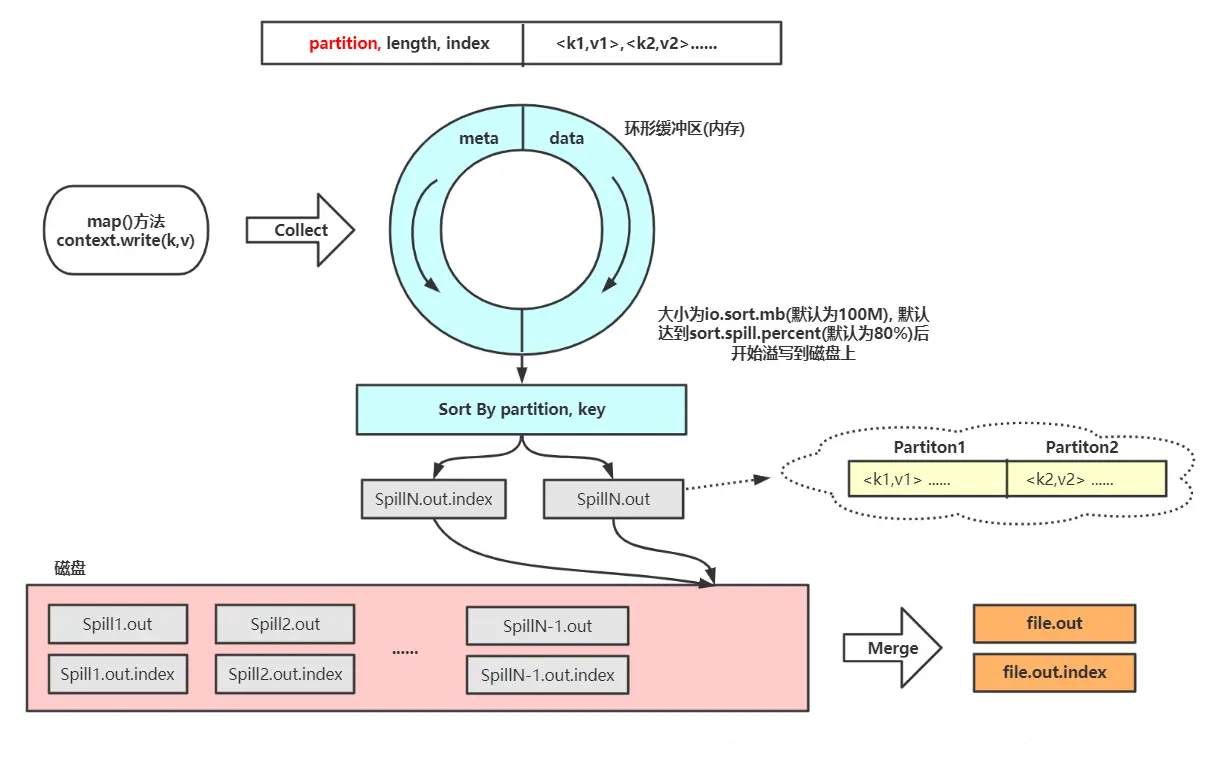
每个 Map 任务的计算结果,都是先写入内存的环形缓冲区(默认100MB,参数 mapreduce.task.io.sort.mb),写到缓冲区容量的 80% (参数 mapreduce.map.sort.spill.percent),就由另外一个守护线程将那 80% 数据写到磁盘上,同时不阻塞缓冲区的写入新结果的操作(期间如果缓冲区满,则这个写操作还是会被阻塞的。),这就是“溢写”——spill 。
Reduce 任务的数量在溢写到磁盘之前就已经知道了,所以会根据 Reduce 任务的数量划“分区”——partition,默认根据 HashPartition 将数据写入到相应的分区。每个分区中,数据都会用快速排序根据 key 排序。如果此时设置了 Combiner ,就再对排序后的结果进行 Combine 操作,使 map 输出更紧凑,减少写到磁盘的数据和传输给 Reduce 任务的数据。每次溢写得到一个新文件,因此当一个 Map 任务计算完成后,本地会有多个临时文件。Map 任务合并多轮递归合并(归并排序),每轮合并mapreduce.task.io.sort.factor 个文件。所有临时文件为一个分区且排序的大文件(保存到 output/file.out),同时生成相应的索引文件(out/file.out.index),合并完毕后,Map 任务将删除所有的临时溢写文件。默认情况下不压缩,使用参数 mapreduce.map.output.compress 控制,压缩算法用参数 mapreduce.map.output.compress.codec 控制。
Combiner 是不能影响计算结果的,适用于求和类如局部汇总,不适用如求平均值等。
一个 Map 任务的输出可能被多个 Reduce 任务抓取;一个 Reduce 任务可能需要多个 Map 任务的输出作为输入。只要有一个 Map 任务完成,Reduce 任务就会开始复制它需要的输出。ApplicationMaster 知道 Map 任务输出和节点对应关系,Reduce 任务轮询 ApplicationMaster 就知道自己所要复制的数据。Reduce 任务用多线程并发地从多个 Map 任务的输出中抓取对应分区的数据到自己本地的内存缓冲区中,如果 Reduce 任务的内存缓冲区达到阈值或缓冲区中的文件数达到阈值,则对数据合并后溢写到磁盘。随着溢写文件的增多,Reduce 任务的后台线程会将这些临时文件再归并排序合并为一个大文件。
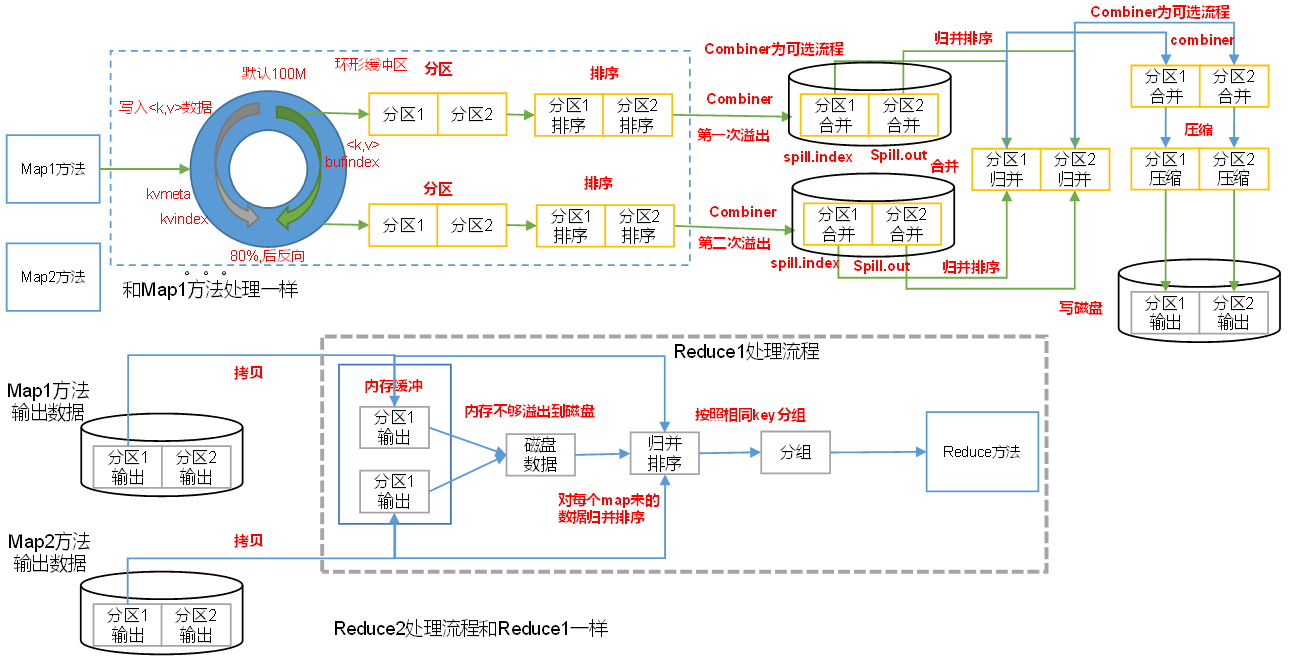
当 Reduce 任务的输入文件确定后,整个 shuffle 过程才结束。
相关参数:
1 2 3 4 5 6 7 8 | |
Reduce 阶段
直到有 5% 的 Map 任务3完成时,ApplicationMaster 才会为 Reduce 任务所需申请资源。
相关参数:
1 2 3 4 5 6 7 | |
每个 Reduce 任务是一个 Java 进程,它读取自己对应的输入文件,按用户实现的逻辑对各每个键作如聚合、计数等计算,计算完毕后写入结果到目标存储中。
Output 阶段
通常,最后计算结果的目标存储时 HDFS 。每个 Reduce 任务对应一个输出文件,名称以 "part-" 开头。
当 ApplicationMaster 收到最后一个任务已完成的通知,把作业状态置为成功后,ApplicationMaster 和 Container 会清理中间结果等临时数据。作业信息由作业历史服务存档,供日后查询。
MapReduce 作业容错
如果是 ResourceManager 失败,那就歇菜了。如果是 NodeManager 崩溃或运行太慢,就停止向 ResourceManager 发送心跳。如果 ResourceManager 超过10分钟都没收到 NodeManager 的心跳,就拉黑它,并按它上面的ApplicationMaster/任务已失败处理。
如果 Container 里任务失败,任务退出前会通知 ApplicationMaster 。ApplicationMaster 标记该任务失败,并释放相应资源。如果是任务意外中止,NodeManager 会注意到并通知 ApplicationMaster ,后者标记该任务失败。如果任务挂起,有一段时间(默认10分钟) ApplicationMaster 没收到进度更新,也会标记该任务失败。任务被标记失败后,ApplicationMaster 会在与之前不同的节点上重新调度该任务执行,默认重试4次,如果4次都失败,则整个作业判定为失败。
相关参数:
1 2 3 4 5 6 7 8 | |
如果 ApplicationMaster 失败,YARN 会尝试重启 ApplicationMaster ,默认重试2次。

Comments