Data Lake ? Lakehouse !
什么是数据湖?
数据湖(Data Lake)这个由 Pentaho 的 James Dixon 提出的术语,并没有一个精确的定义。随着大数据 主要是Hadoop。热潮的兴起出现,在云服务商提供自己版本的“云上大数据平台”过程中炒热。所以关于数据湖的定义就有很多版本,基本上都声称有以下几个特性:
- 数据湖不是数据仓库。
- 数据湖存储容量极大,足以保存一个企业/组织中的所有数据。
- 数据湖中可以存储海量的任意类型的数据,包括结构化、半结构化和非结构化数据。也就是保存的是原始数据,这些数据保持了它们在业务系统中原本的样子。
- 数据湖具备多样化的分析能力,包括但不限于批处理、流式计算、交互式分析以及机器学习。
简单地说,狭义的数据湖指的是数据湖存储 最好是存储在 HDFS 或者云上的对象存储系统上。,就是一个原始数据保存区。广义的数据湖除了数据湖存储,还包括数据湖的管理和分析,即提供一整套工具,提供数据目录(Data Catalog)服务以及统一的数据访问。有些厂商甚至把数据处理任务的调度和管理也当作数据湖的组成部分。
数据湖的相关词汇:
- Data Lake: 数据湖。
- Data Swamp: 数据沼泽,也叫单向湖。
- Data River: 数据河。
只被往里面灌数据,而极少甚至没有输出的数据湖,就被成为单向湖,或叫数据沼泽。
数据河就是在由数据源头就产生清晰干净的有效 所谓的去 ETL 化,数据源头业务就像生态水源一样,不让污水流下去。数据,通过各个河流网(传输管道)流向各个数据消费端。
现有的数据湖产品
开源产品
目前,最有名的开源数据湖产品有 Netflix 的 Apache Iceberg 、Databricks 的 Delta Lake 和 Uber 的 Apache Hudi 。
常见的组件还有:
DaaS
Data Lake as a Service ,就是云服务商提供的数据湖服务。如 Snowflake、亚马逊的 AWS Lake Formation 的 AWS Lake Formation 基本上就是抓取数据源并将数据移动到 Amazon S3 中并构建一个数据目录,该目录描述可用的不同数据集以及哪些用户组可以访问每个数据集。在这个过程中,可以选择将数据转换为 Apache Parquet 或 ORC 等(说好的存储任意格式,保留原来的样子呢?)格式,可以做些去重的操作。服务、微软 Azura 的 Data Lake Storage + Data Lake Analytics / HDInsight Azura Analytics 更像是个 BI 工具,而 Azura HDInsight 是 Hadoop 生态圈工具集合。 、国内阿里云华为云也有相应的产品。
这类服务通常要求用户将数据源通过接入服务存储到云上的数据湖中,使用数据时,再用同一家服务商的云上分析/计算/AI服务来对数据进行处理。用户可以省去很多运维上的麻烦,并且只需支付 但是这些云服务通常都不便宜 ^0^ 存储和实际计算产生的费用。
自实现服务
有的企业不希望将自己的数据直接存储到云服务商那里,会选择自己建立数据湖服务。这种情况下,通常自建的数据湖要么指的就是 Hadoop Data Lake (什么都往HDFS上扔),要么就是某种 RDBMS+Hadoop/Spark/Flink+MPP 的混合架构。相对于使用 DaaS ,自建服务在数据治理、安全管理上需要企业自己的技术团队所花费 但是自建服务花的钱可能会更少 ^0^的时间精力通常会更多。
业界的看法
Forest Rim Technology 数据团队1认为当前数据湖/数据仓库有三个常见问题:
- 缺乏开放性 : 数据仓库将数据转换为专有格式,这增加了将数据或工作负载迁移到其他系统的成本。由于数据仓库主要提供仅 SQL 的访问模式,因此很难运行其他分析引擎,如机器学习系统。此外,使用 SQL 直接访问数据仓库中的数据非常昂贵和缓慢,这使得与其他技术的集成变得非常困难。
- 对机器学习的支持有限 : 尽管有很多关于 ML 和数据管理融合的研究,但没有一个领先的机器学习系统,如 TensorFlow、PyTorch 和 XGBoost,能够很好地在仓库之上工作。与提取少量数据的 BI 系统不同,ML 系统使用复杂的非 SQL 代码处理大型数据集。对于这些用例,仓库供应商建议将数据导出到文件中,这进一步增加了系统的复杂性。
- 数据湖和数据仓库之间的强制权衡 : 超过90%的企业数据存储在数据湖中,这是因为数据湖使用廉价存储,从开放直接访问文件到低成本的灵活性。为了克服数据湖缺乏性能和质量的问题,企业将数据湖中的一小部分数据 ETL 到下游数据仓库,用于最重要的决策支持和 BI 应用。这种双系统架构需要对数据湖和数据仓库之间的 ETL 数据进行持续的工程处理。每个 ETL 步骤都有可能导致失败或引入 bug,从而降低数据质量,同时保持数据湖和数据仓库的一致性是非常困难和昂贵的。除了需要为持续的 ETL 支付费用外,用户还要为复制到仓库的数据支付两倍的存储成本。
现代数仓主要使用 SQL 访问,但并非仅支持 SQL 访问。使用 SQL 访问数仓中经过清洗整合的数据(有数仓本身引擎对海量数据处理的支持)是否比直接访问其他地方的裸数据更“昂贵和缓慢”,我对此持保留意见。目前包括机器学习系统在内的很多系统不能很好地在数仓上工作,这到底有多少是数仓的问题,多少是这些系统的问题,不能一概而论。
Data Lakehouse 通过2一种新的开放和标准化的系统设计来实现与数据仓库中类似的数据结构和数据管理功能3,并将数据存放在数据湖使用的低成本存储系统中:
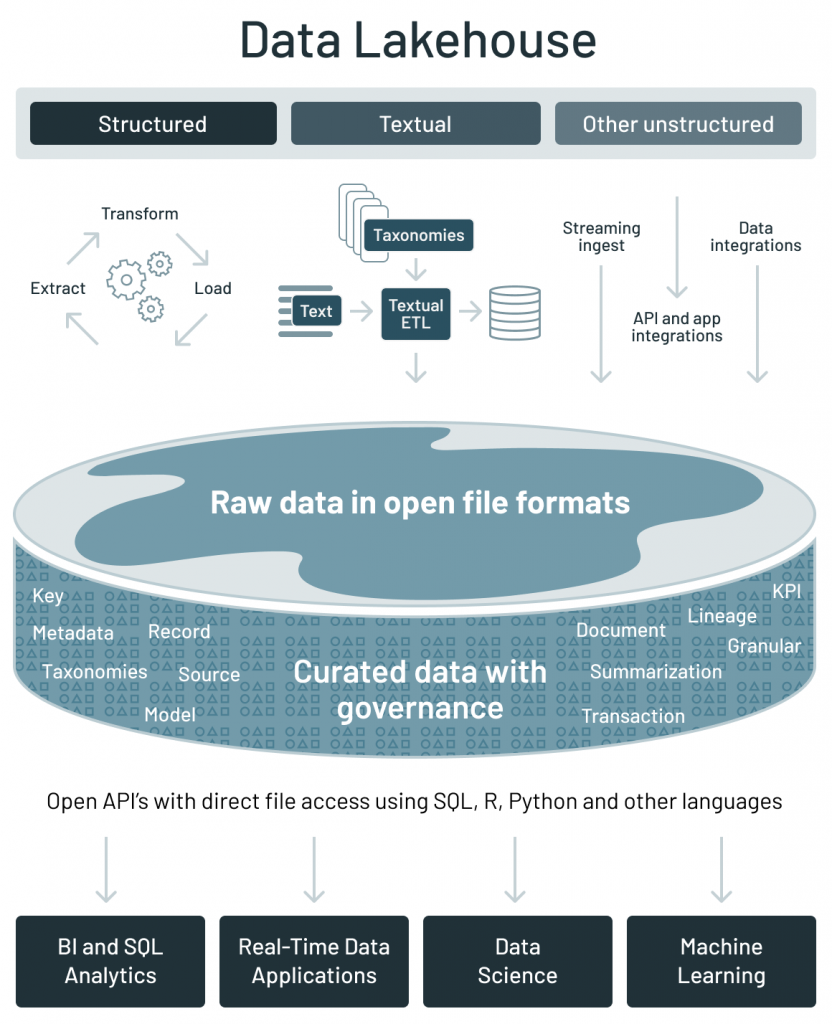
Data Lakehouse 架构解决了上面数据架构的主要挑战:
- 开放性
- 使用开放文件格式:基于开放和标准化的文件格式,如 Apache Parquet 和 ORC;
- 开放的 API:提供可以直接有效访问数据的开放 API,而不需要专有引擎和被厂商锁定;
- 语言支持:不仅支持 SQL 访问,还支持各种其他工具和引擎,包括机器学习和 Python/R 库。
- 原生就支持数据科学和机器学习工作负载;
- 支持多种数据类型:为许多新的应用程序存储、精炼、分析和访问数据,包括图像、视频、音频、半结构化数据和文本;
- 高效的非 SQL 直接读取:使用 R 和 Python 库直接高效的访问大量数据,以运行机器学习实验;
- 对 DataFrame API 的支持:内置的声明式 DataFrame API 具有查询优化功能,可用于 ML 工作负载中的数据访问,因为诸如 TensorFlow,PyTorch 和 XGBoost 的 ML 系统已采用 DataFrames 作为操作数据的主要抽象。
- 数据版本控制:提供数据快照,使数据科学和机器学习团队可以访问和还原到较早版本的数据,以进行审核和回滚或重现 ML 实验。
- 在低成本存储上提供一流的性能和可靠性。
- 性能优化:通过利用文件统计信息,来启用各种优化技术,例如缓存,多维 clustering 和跳过无用数据;
- 模式增强和管理:支持星型/雪花模型等数据仓库模式架构,并提供健壮的数据治理和审计机制;
- 事务支持:当多方并发地读写数据(通常使用SQL)时,利用 ACID 事务来确保数据一致性;
- 低成本存储:Data Lakehouse 架构大多使用了低成本的对象存储,如 Amazon S3、Azure Blob 存储或 Google Cloud Storage 等。
就目前业界的机器学习系统来说,容易以文件的形式提供数据,这确实是一个优势。但是是否就“支持”这些系统的工作负载,也要看这些系统本身是否支持“访问”Data Lakehouse 。
能保存历史的系统自然就有“数据版本控制”。
数据仓库、数据湖以及 Data Lakehouse 比较
| Data Warehouse | Data Lake | Data Lakehouse | |
|---|---|---|---|
| 数据格式 | 封闭的专有格式 | 开放格式 | 开放格式 |
| 存储的数据类型 | 结构化数据,对半结构化数据的支持有限 | 所有类型:结构化数据,半结构化数据,文本数据,非结构化(原始)数据 | 所有类型:结构化数据,半结构化数据,文本数据,非结构化(原始)数据 |
| 数据访问 | 仅支持 SQL 访问,无法直接访问文件 | 通过开放 API 可以直接访问到文件,并且支持 SQL、R、Python 以及其他语言 | 通过开放 API 可以直接访问到文件,并且支持 SQL、R、Python 以及其他语言 |
| 可靠性 | 通过 ACID 事务提供高质量、可靠的数据 | 低质量、数据沼泽 | 通过 ACID 事务提供高质量、可靠的数据 |
| 数据治理和安全 | 为表提供行/列级的细粒度安全性和治理 | 安全性不佳,因为需要将安全性应用于文件 | 为表提供行/列级的细粒度安全性和治理 |
| 性能 | 高 | 低 | 高 |
| 扩展性 | 按比例扩展成本会成倍增加 | 扩展可以以低成本保存任何数量的数据,而不考虑类型 | 扩展可以以低成本保存任何数量的数据,而不考虑类型 |
| 用户场景支持 | 仅限于 BI、SQL 应用程序和决策支持 | 仅限于机器学习 | 一个架构就支持 BI、SQL 以及机器学习 |
我的看法
先说我总的看法:狭义的数据湖有一定存在的意义,对某些场景的需求有比传统数仓更好的支持;广义的数据湖则是一个大“坑”,一个纯粹的营销词汇。
在数据仓库的架构里,本来就存在对海量的原始数据存储区域,对接各种异构的结构化或非结构化的数据源,也为数据血缘管理所覆盖。这些不是数据湖的首创。单独把这个存储子系统分离出来,称为数据湖,是有一定意义的。因为过去的数据仓库体系里,这个原始数据的存储区域往往不对终端用户开放。终端用户只能访问数据仓库或者数据集市中,经过建模和处理后的数据。现在很多情况下(特别是互联网行业),数据的需求很不明确、业务经常性地变动,或者需要频繁地对原始的数据进行探索。传统的数仓的原始数据经过数仓再到应用端给用户访问的链条太长了,对这些类型的需求的支持不够。
现在为这个存储区域加上权限控制、数据目录,然后让终端用户 包括人类用户和程序也可以访问。这就能更快速地适应上层数据应用的变化。这就是狭义的数据湖,确实扩展了数据仓库的能力。
广义的数据湖就是一个概念箩筐,什么都往里面装。它把数据采集、数据存储、数据治理、机器学习、数据分析等都涵盖了一通,基本上就是去除了建模的数据仓库。除了作为云服务商推销自己的云上大数据服务的营销词汇外,没有提供任何比数据仓库更好的新东西。数据仓库只是一个方法论,它的实现本身也在与时俱进。仅仅对它各个子系统的技术选型进行变更或者扩展了数据的用途,并不意味着一个新的概念就产生了。广义的数据湖并不是下一代的“数据仓库”。
更重要的是,隐藏在广义的数据湖背后的一些前提假设,使得建立/使用它的过程成为一个“大坑”。
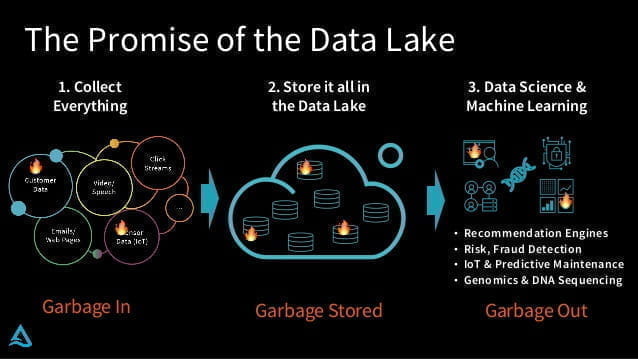
广义的数据湖声称它“存储一切”。然而并不是所有的数据都值得存储,存储也是要成本的。纯粹地存储数据并不能提供什么价值,有句老话叫做 Garbage in, garbage out. ,看起来数据湖省去了 ETL ,实际上只是把数据转换、规范的操作复杂度与时间成本转移给了终端用户。特别对非互联网企业,许多数据的结构不像互联网行业那样简单。广义数据湖实际上会使得这些企业在存储和处理两个方面的成本都增加了。
如果你观察许多厂商画出来的数据湖架构图,你就会发现这些广义的数据湖实际上实现的是独立型数据集市架构 通常把数据仓库体系分为3种类型:Inmon的企业信息化工厂、Kimball的维度数据仓库和独立型数据集市。。独立型数据集市被很多机构应用,因为它能迅速、廉价地获得结果。但是当企业的需求开始有多个主题区域时,这种架构短期的成功会带来长期的问题。
也许将来在这数据湖的热潮过后,最终能落地的是 Data Lakehouse ,狭义的数据湖作为 repository ,在这之上是混合多种技术实现的数据仓库。

Comments